« これ何? | メイン | まだマテリアルいじってたり »
2006年03月12日
ウェブ進化論

ISBN:4480062858
買ったのは 2 週間ほど前だったのですが「坂の上の雲」を読んでたこともあり、棚に置き去りにしてありました。しかし今日の「サンデープロジェクト」でこの本が紹介されたこともあり「いい加減読んでしまわないといけないな」と思い立ち、読みはじめました。読了するまでに 3 時間半ほどかかってしまいましたが、意外とすんなり読めたと思います。
これは著者の梅田さんの文章を「CNET Japan Blog - 梅田望夫・英語で読むITトレンド」や「My Life Between Silicon Valley and Japan」で慣れていたためだろうと思います。しかしこれらの前提知識がない人が読むと、意外とチンプンカンプンなんじゃないかな、と思います。これは前提知識の量にもよりますね。
どこで読んだか忘れてしまいましたが、この「ウェブ進化論」で書かれている内容は全てオンラインで読むことができます(本文をそのまま読める、という意味ではなく、梅田さんの考え方を彼の Blog から読み取ることができる、という意味)。しかし日本の権威に対してそれを説明するにはオフラインで──活字になってるメディアでないと駄目であり、そのためもあってこれは出版される必要があった書籍である、という内容のものです。意外とこの評は的を射ており、本として出版されたことを契機に「サンデープロジェクト」においても『インターネットの「こちら側」と「あちら側」』という、随分前から梅田さんがいってきた内容が田原さんの口をとおして語られることにもなりました。未だに日本においては書籍は立派な権威であり続けています。
しかしこの本を読んではじめて気付かされたことも多く、やはり本というメディアは重要であると思います。Blog を読むということは、勿論 Blog オーナーによって編集されたエントリを読むということですが、本になるということは専門の編集者の意見も反映されているわけです。日々更新される Blog は意外と「読み飛ばし」が発生することもあり、記事に前後の関連性が無い読みきりものにおいては意図的に読み飛ばしたのか偶然読むことができなかったのかにかかわらず、ずっと読まないでいてしまう状態も発生します。本という fixed な状態になってもらえると、「最初から最後まで」という固まった状態が維持されているため安心して読むことができます。そこには編集という作業が強く働いているわけですが、この編集という仕事は web 的にいうと Google などの検索エンジンをとおす、という意味にかさなります。
さて、それはおいておくとして、この本ではじめて気づかされたことに関して。Google が「ベスト・アンド・ブライテスト」主義の技術者集団であることは CNET での Blog を読んでいるときに認識していた Google 像ですが、この本でおもしろかったのが、ロングテール部への注目とそれを実現する技術に関してです。簡単にまとめると、
ネット世界とリアル世界のコスト構造の違いが、ロングテールに関する正反対の常識を生み出している(p111)という部分になります。これは序章でも語られており、
放っておけば消えて失われていってしまうはずの価値、つまりわずかな金やわずかな時間の断片といった無に近いものを、無限大に限りなく近い対象から、ゼロに限りなく近いコストで集積できたら何が起こるのか。ここに、インターネットの可能性の本質がある。(p20)と同じことをいっています。Google はそれを実現するための技術を有しており、それは人間が行うわけではなくプログラムが行います。勿論その成果は Google では広告収入にあたるでしょうし、Amazon ではネット通販の利益にあたります。
おもしろいもので、こういった考え方は日本ではマンガやアニメにおいて顕著にみることができます。それはドラゴンボールの元気玉であったり、攻殻機動隊 S.A.C. 2nd GIG のクゼの軍資金調達方法であったりなどです。両方とも実現するためには傑出した技術が必要というあたりは、仮想・現実の世界それぞれにおいて共通しています。
さてもう一点、この本で 2 箇所しかない図の 2 個目に関してです。
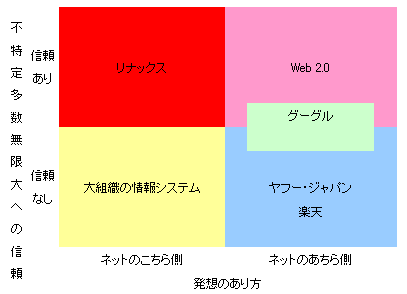
Fig.1 ウェブ進化の方向
この「不特定多数無限大への信頼」の「信頼あり」と「信頼なし」というカテゴライズは、この図が現れる以前に全編において語られていますが、ここで思ったのが暗号の話です。
暗号技術入門に以下の文があります。
暗号アルゴリズムを秘密にしてセキュリティを保とうとする行為は、一般に隠すことによるセキュリティ(security by obscurity) と呼ばれ、危険で、かつ愚かなこととみなされています。(p16)勿論これは「情報を隠すことによる市場内での優位さ」を対象にしたい部分ですが、公開されている Google の技術 (この本では API と言われている部分) と、公開されていない Google の技術 (Google を Google たらしめている OS やデータベースに関する部分)の線引きが重要であると思います。
企業が利益を生む仕組みを全て公開することはありえませんが(特許ビジネスはまた別方向として)、情報を含めて図をちょっといじると以下の様になるかな、と思います。
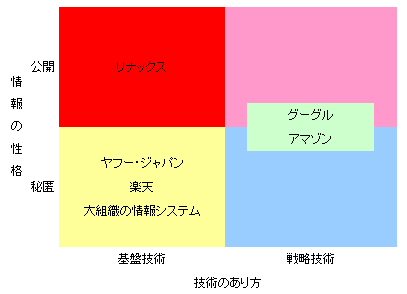
Fig.2 ちょっといじったもの
ここでの基盤技術と戦略技術というのは、梅田さんの以下のエントリの概念です。
- [コラム] 「ライブドアの技術の話」と「技術指向の経営」について
http://d.hatena.ne.jp/umedamochio/20060127
戦略技術というキーワードは残念ながらこのエントリ以降使われていませんが、これからも注目していきたい部分です。
なんというか、考えながら書いていますが、どうも考えが発散方向に進んでしまって結論がでませんね。。
投稿者 napier : 2006年03月12日 15:48
トラックバック
このエントリーのトラックバックURL:
http://will.squares.net/mt/mt-modified-tb.cgi/317
このリストは、次のエントリーを参照しています: ウェブ進化論:
» 梅田望夫さんと「残念」の周辺 from N a p l o g
日本のWebは「残念」 梅田望夫さんに聞く(前編) (1/3) - ITmedi... [続きを読む]
トラックバック時刻: 2009年06月14日 05:06
